DuckDB (文件)
我们通过 DuckDB 支持文件连接。要添加连接,请在**连接数据源**部分单击 **DuckDB** 选项。
信息
支持的文件格式
- CSV 文件
- JSON 文件
- Parquet 文件
支持的数据类型
- BIGINT
- BIT
- BLOB
- BOOLEAN
- DATE
- DECIMAL
- DOUBLE
- INTEGER
- REAL
- SMALLINT
- TIMESTAMP
- VARCHAR
- ARRAY
- BOOLEAN
- INTEGER
- DOUBLE
- DECIMAL
- VARCHAR
- TIMESTAMP
- DATE
连接
填写连接设置: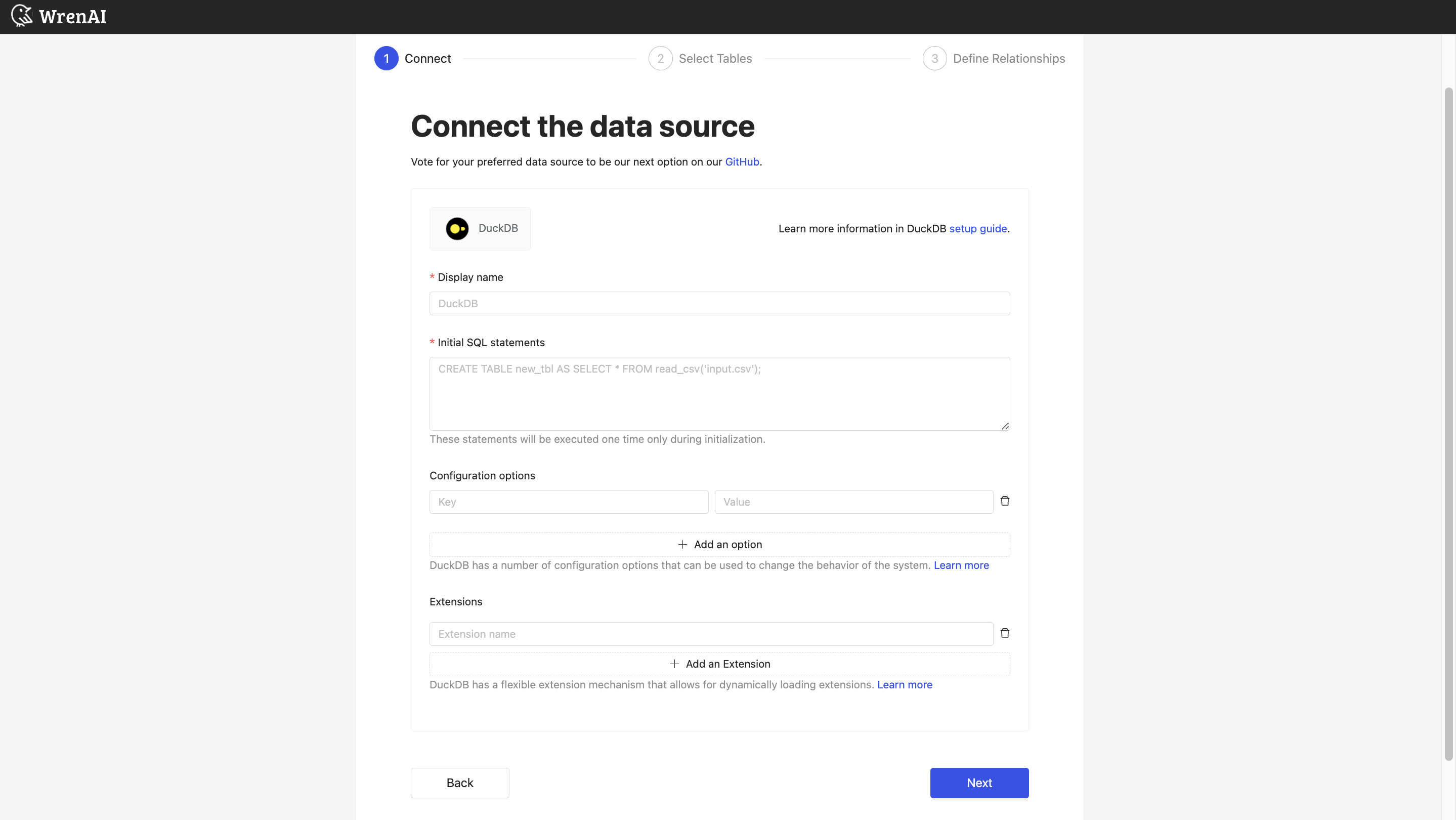
显示名称
数据库在 Wren AI 界面中的显示名称。
初始 SQL 语句
连接文件的第一步是将数据加载到 DuckDB 中。DuckDB 提供了多种数据摄取语句,允许您填充数据库。有关从不同文件类型加载数据的方法,请参考 DuckDB 文档。
以下是一些示例
- CSV 文件
- JSON 文件
- Parquet 文件
- 多个文件
CREATE TABLE new_tbl AS SELECT * FROM read_csv('input.csv', header = true);
CREATE TABLE new_tbl AS SELECT * FROM read_json('input.json');
CREATE TABLE new_tbl AS SELECT * FROM read_parquet('input.parquet');
CREATE TABLE tbl1 AS SELECT * FROM read_csv('tbl1.csv', header = true);
CREATE TABLE tbl2 AS SELECT * FROM read_json('tbl2.json');
信息
您可以从本地路径或云存储 URL(例如 AWS S3)读取文件。
配置选项
DuckDB 有许多配置选项可用于更改系统的行为。您可以根据需要在此部分设置配置,或者留空以使用默认配置。填写配置时,请将每个配置名称和值设置为一对。有关配置选项的详细信息,请参考 DuckDB 文档。
扩展
DuckDB 具有灵活的扩展机制,允许动态加载扩展。内置扩展和自动加载扩展将自动加载。如果需要,您可以通过填写扩展名称来添加其他扩展。有关官方扩展列表,请参考 DuckDB 文档。
单击**下一步**开始连接并进入下一步。
选择表
在此步骤中将列出您已连接文件的所有表。选择您要在 Wren AI 中使用的表。每个选定的表都将创建一个数据模型。请参阅建模文档,了解有关数据模型的更多信息。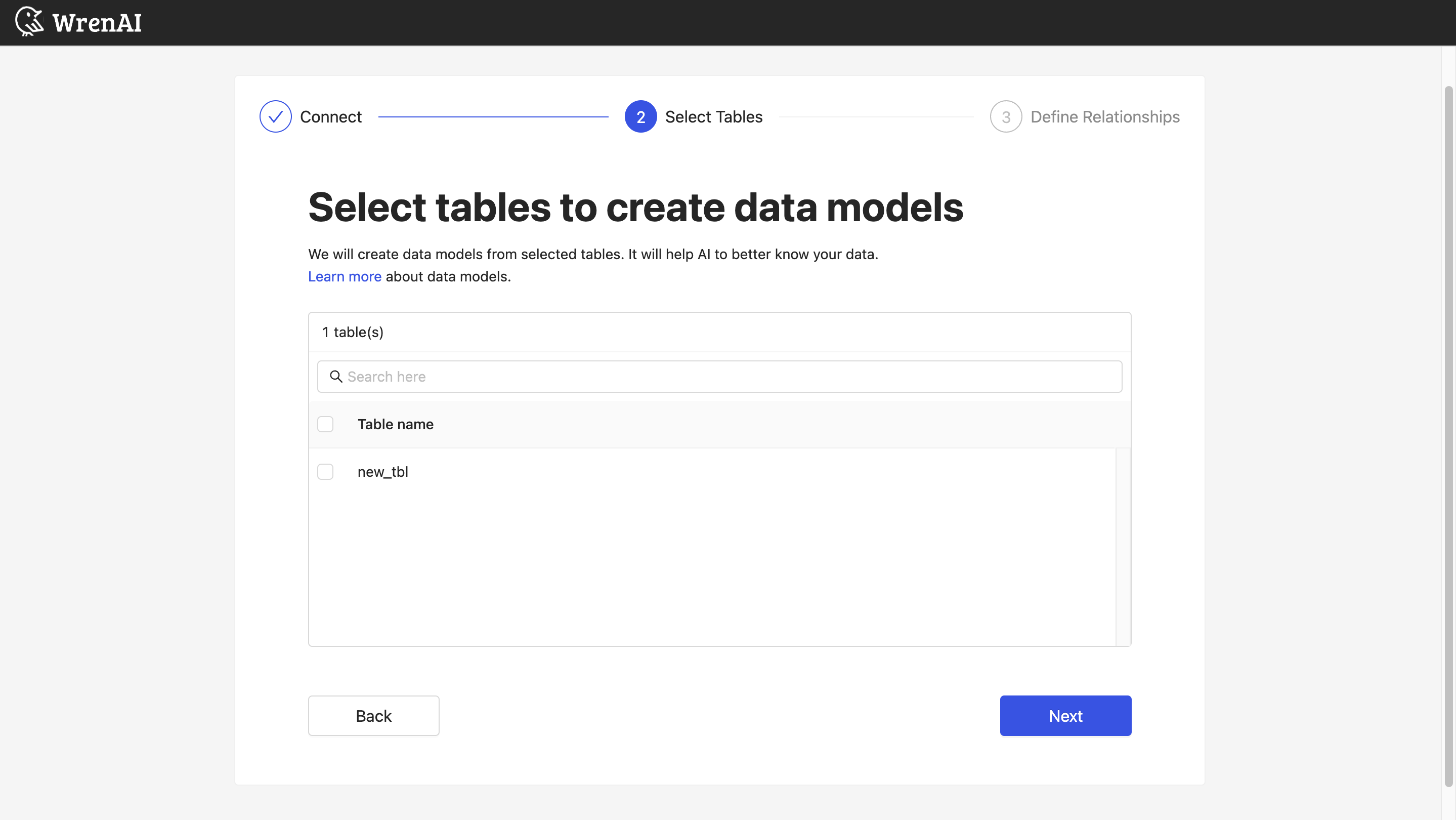
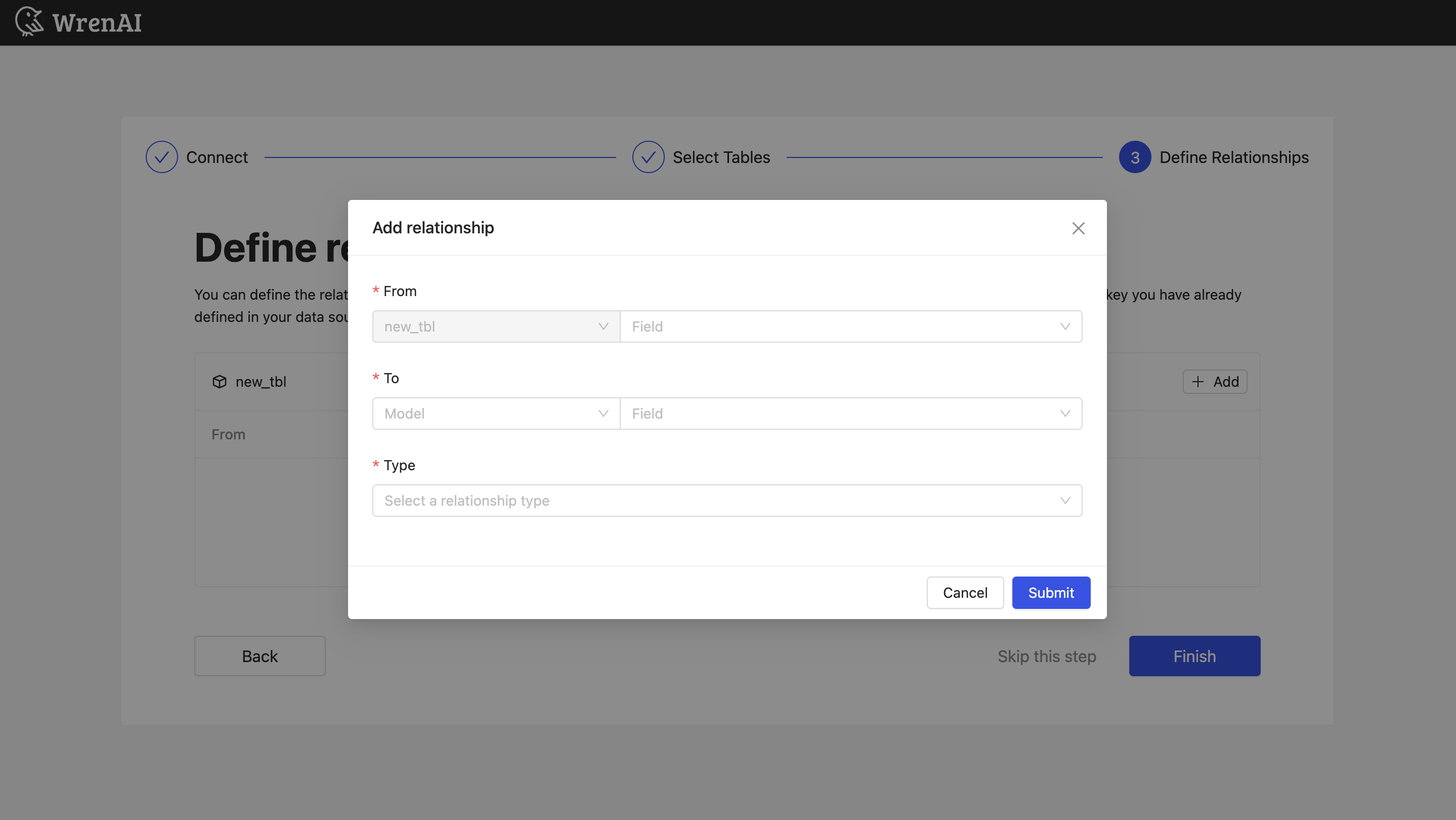
定义关系
在此步骤中定义所选表之间的关系。您可以通过单击表块上的**添加关系**按钮来添加关系。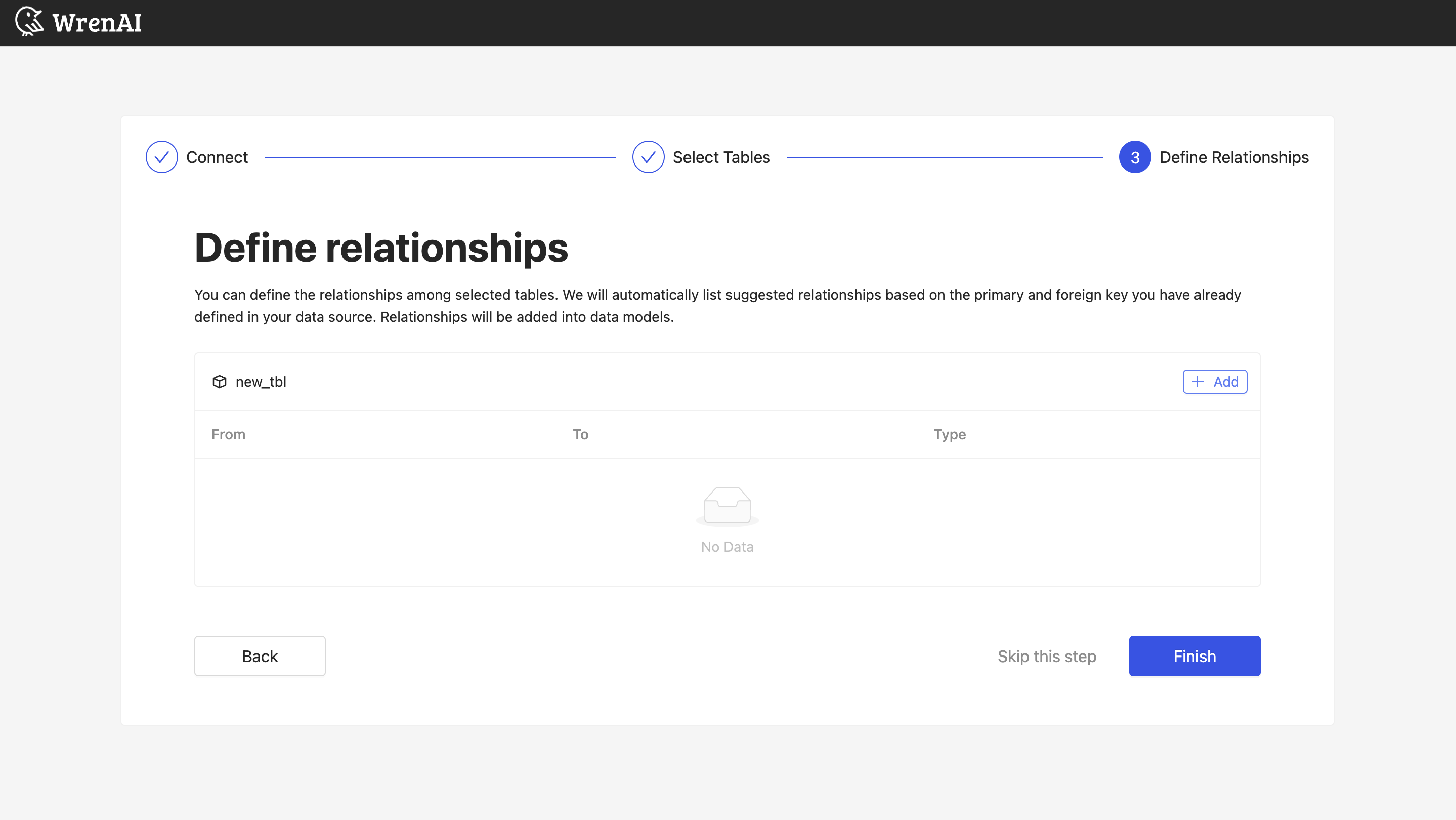
在关系中定义以下属性
- From: 选择此关系的左侧表和列。
- To: 选择此关系的右侧表和列。
- 关系类型: 选择关系类型。
在建模 - 使用关系中查找更多关系信息
您也可以跳过此步骤并完成连接。